Speed and visibility with IaC security
Automate security guardrails early in IaC development to avoid cloud misconfigurations
Don’t let security become a roadblock
IaC security is critical to avoiding cloud breaches. But it’s only effective if it keeps you safe without slowing you down.
Mistakes multiply with infrastructure as code
Misconfigurations are the top cause of data breaches. And a single misconfiguration in IaC can be amplified when scaled up.
Siloed infrastructure as code tools obstruct visibility
Visibility is crucial for cloud security. Yet siloed IaC tools and processes often inhibit visibility in IaC development.
Infrastructure as code authors aren’t security experts
IaC authors aren’t security experts. But, with IaC, they control cloud configurations, which can lead to costly mistakes.
Report
Take Six Steps To Secure Infrastructure As Code
Forrester’s recent report provides valuable insights into securing IaC, including six key practices that your team can adopt from build time to runtime.
Access Report
BENEFITS
Deliver secure code without slowing down
Find and fix misconfigurations before they’re deployed, without disrupting the developer experience.
From shove left to shift left
Meet IaC authors where they work by enabling them to secure their code without disrupting their workflows or being security experts.
From costly to cost efficient
Save time and money by fixing misconfigurations at the earliest (and cheapest) possible point.
From chaos to control
Give security teams centralized visibility and control with a single platform. Then easily share this data across your organization.

OUR APPROACH
Speed and visibility with one platform
No more fragmented IaC tools. In one platform, security teams gain centralized visibility, and developers can fix issues without slowing down.
Respect the developer experience
- Deploy Lacework in minutes to automatically identify IaC files, find misconfigurations, and track changes to code repositories
- Enable developers to identify IaC security issues natively within workflows by commenting on pull requests as part of standard code review
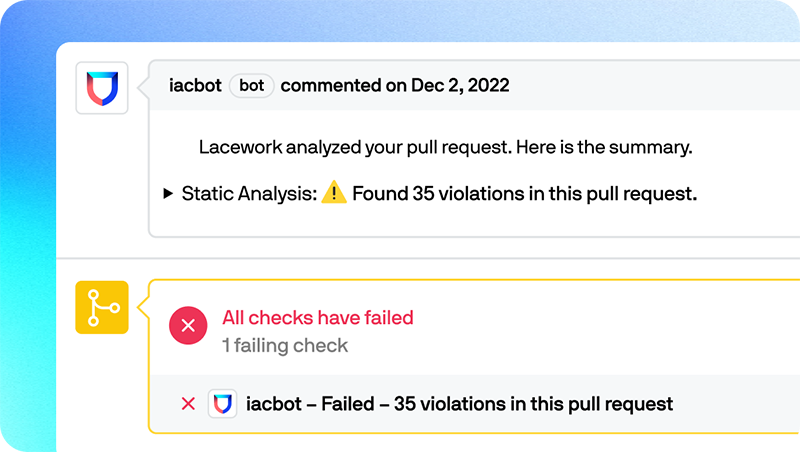
Democratize access to data for all teams
- Centralize data and gain a unified experience with a single platform
- Enable security, compliance, development, and operations teams to collaborate on violations, policies, and remediation efforts in one place
- Empower security teams to suggest code fixes via automated pull requests
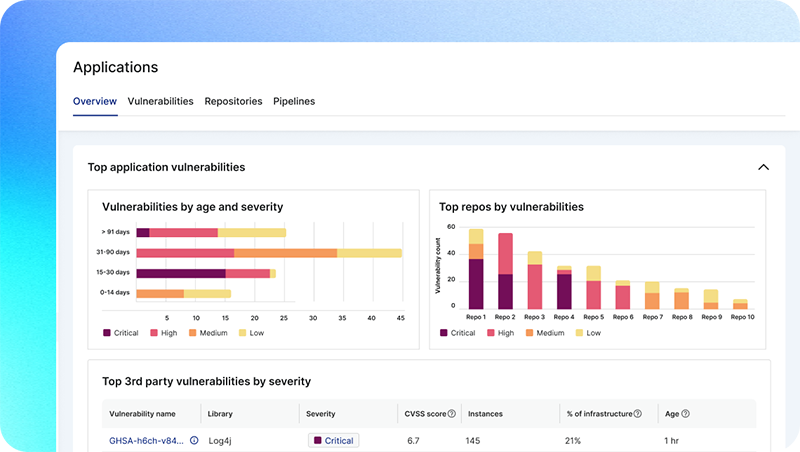
Empower developers to fix issues fast
- Arm developers with automated remediation guidance within existing toolchains
- Allow developers to independently address IaC security and compliance issues without relying on security teams
- Provide feedback in the CI build output to help teams track security issues as part of their CI/CD testing processes

Build custom policies with Open Policy Agent (OPA)
- Build and manage OPA-based custom IaC policies to meet your unique and evolving business needs
- Enforce tagging as a security hygiene best practice by blocking improperly tagged code
- Adopt a policy-as-code framework to efficiently manage your infrastructure as code


“We were super impressed with the capabilities we saw in the Lacework demo. We were keen to see that it lived up to the promise: the unintrusive setup, the simple dashboards, the ease of use.”
Nic Parfait
Head of Engineering
Read case studyCommon questions
Infrastructure as code (IaC) is used to automate the configuration and provisioning of cloud services. IaC security is the assessment of this code to ensure that the usage and configuration of cloud services conform to industry and company specific security and compliance standards.
Cloud security follows a shared responsibility model. Cloud service providers are responsible for security “of” the cloud — the hardware, software and other infrastructure required to provide their services. Users of these services are responsible for security “in” the cloud — including the configuration of each cloud service they use.
Cloud misconfiguration is a leading cause of cloud data breach. Assessing IaC security early in development can dramatically shrink a cloud attack surface and can save substantial time and money associated with fixing security flaws.
Here are a few infrastructure as code security best practices:
- Respect existing developer workflows and limit the amount of security-related context switching by integrating automated security and compliance checks seamlessly into their existing toolchains.
- Reduce the amount of overall IaC tools. Ensure IaC security is part of a cloud-native application protection platform (CNAPP), so that teams have the centralized visibility and data required to work together in responding to cloud misconfigurations.
- Make sure your infrastructure as code tools empower developers to self-service security and compliance violations so that they can work uninterrupted, without having to wait for security teams to get involved.
- Ensure your infrastructure as code tools implement a consistent policy as code framework, like OPA, so that teams can easily manage and govern policy as cloud deployments scale.
Resources & Insights


Featured Insights